


「喂图」这种行为一般不具有构成侵犯著作权罪的风险,但若是通过「爬虫」并避开相应的技术措施对 AI 绘画进行「投喂」,将可能构成侵犯著作权罪。
撰文:肖飒团队
核心提示
- 根据《生成式人工智能服务管理办法(征求意见稿)》第二十条,AIGC 的服务提供者「构成犯罪的,依法追究刑事责任」。
- AI 绘画服务提供者「投喂」AI 绘画不侵犯复制权与信息网络传播权,不会构成侵犯著作权罪。
- 若著作权人采取技术措施,AI 绘画服务提供者通过「爬虫」避开技术措施获取图片并「投喂」,则可能构成侵犯著作权罪。
AIGC 的服务提供者虽然仅是根据用户的要求进行相应的输出,用户具有相当强的自由决定如何使用,但作为平台也需要承担一定的社会责任。国家互联网信息办公室 2023 年 04 月 11 日发布的《生成式人工智能服务管理办法(征求意见稿)》中第二十条提到,aigc 服务提供者「构成犯罪的,依法追究刑事责任」。飒姐团队之前已经在合规 | 「投喂」AI 作画,或成侵权作品?!一文中研究过有关「投喂」的法律性质,我们从 AI 创作者的角度出发,认为一般情况下 AI 创作并不会构成侵权行为,但仍需个案判断。今天我们将从 AIGC 服务提供者的角度,聊一聊涉及到的刑事法律问题。
首先我们再来回顾一下 AI 绘画的原理。具体而言 AI 绘画有三层机制。第一层是基础逻辑层。AI 绘画能完成风格上的迁移。第二层是数据库。在第一层基础逻辑的基础上,AI 就需要大量的「喂图」来进行学习和总结,获得不同的图像参数范例。这一步就是所谓的深度学习过程。第三层是创造性输出。AI 绘画的厉害之处在于其生成的图片不仅是符合文字描述的,更重要的是能够创造出符合美学逻辑的图像。在上一步的基础上,AI 需要通过人类工程师告诉它哪一种结果是美的,并调整增加此类输出结果的比重。这一步就是范例学习。
通过长期往复的深度学习和范例学习,AI 就掌握了一些通用的绘图规律,并通过总结规律修正模型。因此,AI 绘画大体上又可以分为三个阶段的工作,数据收集、数据处理、生产图像。「喂图」是其中第二步「深度学习」的核心,也是饱受争议的一种行为。优秀的 AI 绘画模型,必然少不了庞大的数据库支撑,因此许多服务提供者会选择使用「爬虫」获取大量数据。篇幅有限,以下我们主要分析对于 AI 绘画服务提供者而言,AI 绘画服务提供者通过「爬虫」获取图片后「投喂」AI 绘画这种行为是否有构成侵犯著作权罪的风险。
《中华人民共和国著作权法》(以下简称《著作权法》)对于著作权人的权利保护采取的是列举的方式,并在第五章「著作权和与著作权有关的权利的保护」详细列举了诸多侵犯著作权的行为。但在《刑法》第二百一十七条侵犯著作权罪中仅列举了六项行为,而这还是在最近的一次刑法改动——《中华人民共和国刑法修正案(十一)》(以下简称《修十一》)——中从四项增加至六项。《修十一》对该条作了较大改动,不仅提高了刑期上限,还对构成要件做了一定的改动。一方面,除「复制发行」行为构成侵犯著作权的行为要件外,「通过信息网络传播」行为也同样构成侵犯著作权的侵权行为要件;另一方面,《修十一》还针对「采取避开或破坏技术措施」的行为加设了约束。
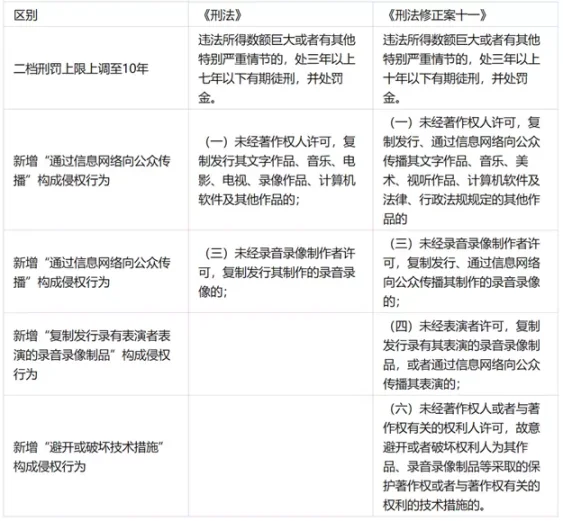

关于数据收集方面,以下我们主要讨论是否会触犯本条第一项与第六项。
其中第一项主要涉及复制发行与信息网络传播的问题。
关于复制发行的规定保护的是著作权人的复制权。根据《著作权法》第十条第五项,复制权是指:「以印刷、复印、拓印、录音、录像、翻录、翻拍、数字化等方式将作品制作一份或者多份的权利」。复制是以现有已知或未知的方式,将作品固定在有形的物质媒介上,使得作品被他人感知、传播、复制。因此我们认为一般要构成著作权法上的复制行为,该行为应当在有形物质载体上再现作品。只有通过一定的物质形式,作品才能获得固定性,使原作和复制件具有明显的对比关系。而将其作为数据存储,获得其图像参数范例时,尚未进行输出的时候,我们很难认定其侵犯了作者的复制权。
关于信息网络传播的规定保护的是著作权人的信息网络传播权。根据《著作权法》第十条第十二项,信息网络传播权是指以有线或者无线方式向公众提供作品,使公众可以在其个人选定的时间和地点获得作品的权利。而一般我们认为,AI 绘画服务提供者的数据库是非公开的,公众没有机会直接获得作品。那么另一方面,公众能否通过使用 AI 绘画服务间接获得原作品呢?我们认为也是不大可能的。这类的 AI 生成模型的核心技术能力就是,把人类创作的内容,用某一个高维的「向量」进行表示。如果这种内容到向量的「翻译」足够合理且能代表内容的特征,那么人类所有的创作内容都可以转化为这个空间里的向量,那么此时我们有可能通过给出所有的向量从而还原最初的内容。但目前我们的「翻译」显然还不具有这种能力,即大量现实世界的内容是无法被 AI 系统的「向量」所概括。因此我们认为即使想通过关键词等溯源,公众依旧是无法获取原作品的,AI 绘画服务不会侵犯著作权人的信息网络传播权。
其中第六项主要涉及「反向工程」的认定问题。《著作权法》第四十九条赋予了著作权人采取技术措施的权利,现实中随着人们权利意识的增强也往往开始采取设置浏览权限等方式保护自己的作品,此时「爬虫」无法直接获取作品,但通过一定的技术手段也可避开技术措施获得作品。目前我国还没有关于因通过「爬虫」绕过或破坏技术措施获取数据而认定为侵犯著作权罪的裁判案例,但存在因为未经著作权人许可,复制游戏数据后修改其作品采取的保护著作权或者与著作权有关的权利的技术措施,而被认定为侵犯著作权罪的案例(案号:(2022)沪 0107 刑初 81 号);民事案件中,也存在将通过「爬虫」避开技术措施认定为侵犯信息网络传播权的裁判((2016) 京 73 民终 143 号)。综上,我们并不排除通过「爬虫」绕过或破坏技术措施获取数据而被认定为侵犯著作权罪的可能。
同时根据《著作权法》第五十条,避开技术措施是有例外情形的,即满足条件的情况下是允许避开技术措施的。

但显然经过检索,我们无法将「爬虫「行为归类入以上范围内。以上谈论的《修十一》对侵犯著作权罪第六项的更改是跟随 2020 年《著作权法》修法的产物,其承接了对直接规避行为与间接规避行为均持反对的态度。但学界大多数观点认为,我们不应禁止直接规避行为,即对于直接规避行为,应通过检阅其后续使用行为是否侵犯著作权,构成直接侵权,从而对其进行规制。循此思路,则具有审查是否符合条件较为宽泛的「合理使用」之余地,即我国《著作权法》中「著作权的限制」。不过退一步而言,即使采取了以上立法观点,「喂图」也很难归入「合理使用」的范畴以内。
综合以上,我们认为「喂图」这种行为一般不具有构成侵犯著作权罪的风险,但若是通过「爬虫」并避开相应的技术措施对 AI 绘画进行「投喂」,将可能构成侵犯著作权罪。
写在最后
「版权」在 18 世纪正式出现并发展,于 1709 年由英国《安娜女王法》的颁布而得此确立,距今已有三百多年。版权或著作权的本质是通过赋予其一定的垄断对智力劳动成果进行法律保护,从而鼓励智力劳动。随着时代变迁,科技进步,人们的智力成果呈现多样化的态势,著作权通过正面列举认定的方式进行保护,必然会较于时代发展滞后。一方面,我们应当鼓励共享与开放的未来,在信息化时代数据共享使用将是时代浪潮;但另一方面,我们也应当注意在 AI 迅速发展下的现实场景下应当在何种程度上以何种方式保护著作权。目前无论提供 AIGC 服务的行为性质如何,其在绘画领域的发展已经对该行业产生了巨大的影响。大量的原画师失业已是不争的事实,「AI 绘画师」这一职业却冉冉升起。我们在考虑 AIGC 相关创作是否违反有关知识产权的相关法律规定的同时,是否应当给予更多人文视野的关怀于这些不愿接纳 AIGC 时代的人们呢?
发布者:Web3创投,转载请注明出处:https://nft.aiju.com/news/81763.html,如涉及作品内容、版权及其它问题,请联系本站!
『声明:根据央行等部门发布的《关于进一步防范和处置虚拟货币交易炒作风险的通知》,本文内容仅用于信息分享,不对任何经营与投资行为进行推广与背书,请读者严格遵守所在地区法律法规,不参与任何非法金融行为』