


BlockGPT 通过对交易的自然性进行排序,基本能够实现实时检测出大部分异常交易。
嘉宾:Yu GAI,伯克利研究生
整理:aididiaojp.eth,Foresight News
本文为 Web3 青年学者计划中伯克利研究生 Yu GAI 视频分享的文字整理。Web3 青年学者计划由 DRK Lab 联合 imToken 和 Crytape 共同发起,会邀请加密领域中知名的青年学者面向华语社区分享一些最新的研究成果。


大家好,我是 Yu Gai,今天要分享的内容是关于大型语言模型在区块链异常检测方面的应用。
我们的研究背景主要是区块链行业在最近的一段时间内飞速发展,目前已经有非常高的市值。但是在区块链行业快速发展的同时,区块链的用户其实也频繁遭受各种各样的攻击,承受了巨大的损失,因此区块链需要引入一个比较好的异常检测系统。
我们算是比较早地尝试用语言模型做异常检测,我们发现语言模型 BlockGPT 可以非常有效的判断出哪些交易可能是异常行为或者攻击,并且判断不基于人来制定规则。我们数据集当中有 124 个攻击,BlockGPT 成功将其中的 20 个判断成最不可能发生的攻击,20 个是第二不可能发生的攻击,然后 7 个是第三最不可能发生的攻击。我们同时发现 BlockGPT 运行的速度还是不错的,它每秒可以处理大约 2000 笔交易,这样的话它基本上已经可以在主流的区块链中投入使用。
首先我来介绍一下我们的攻击模型,我们假设是有一个计算资源有限的攻击者,他能做的事情就是通过在平台上执行交易,从而利用智能合约当中的一些弱点来获利。具体来说它可以有两种方式来执行交易,一种是直接把它的交易通过 P2P 网络广播到整个区块链上,经过验证之后,攻击者的交易就被写进了区块链,然后攻击者就能够获利。因为区块链它本身是不可更改的,交易一旦进入链上就不可更改,所以说它这个套利行为也不可能被逆转。然后还有另外一种是他会把自己的交易不通过 P2P 网络给广播出来,而是把它隐藏起来,通过一些比如说抢先交易和对预言机攻击等。这些交易我们不能直接在区块链里面观测到。我们主要考虑的是这两类攻击者,在第一类攻击者当中,这个交易一旦被广播出来,他就可以直接检测到,然后这样的话就可以直接发出预警。第二种的话因为它不会直接广播出来,所以在交易被写入区块链之前,BlockGPT 是看不到的,所以我们只能在它被写入区块链之后来识别出它是一个异常或者攻击交易,在识别出来之后就可以发出预警。

接下来讲一下基于机器学习的异常检测会遇到的一些问题。传统的基于机器学习的异常检测系统会使用一个二分类的算法,即给定一个交易,我们通过分类器把它分成攻击交易或者正常交易。这个做法需要较大的训练数据,然而作为一个新兴的领域,有标注的攻击数据其实是不多的,而且攻击的方法也在日新月异的改变,所以去训练这样一个二分类算法其实是有很大难度的。
我们在这篇文章里尝试了一个新的方法,我们基于对交易的自然性进行排序。具体来说,我们给定一个 DeFi 应用,BlockGPT 它首先会估计所有交易的自然性,估计是基于交易进行的,我们会对其中 K 个最不可能的交易发出预警。每一个 DeFi 应用它都可以调整 K 这个参数。如果 K 设的较大,就会到就会增加预警的数量,但是也会增加预警当中假阳性出现。这个做法的好处是不需要有标注的数据,也就是说不需要告诉算法,这一个交易是不是攻击,只需要去训练 BlockGPT,然后 BlockGPT 对于每个交易的自然性进行一个排序就好了。
它其实还有一些优势,例如它是由数据驱动,而不是基于规则驱动。这样的话我们不需要再去手工设计一些规则,只需要把数据给 BlockGPT 就可以了。也是因为这个原因,它可以检测到一些非常新的交易,这些交易可能是既往规则不能够判断出来的。因为它其实是一个基于自然性的一个算法,只要一个交易它的可能性比较低,那么这个 BlockGPT 就会给出预警。还有它和基于规则算法不一样的地方是它可以去检测到一些不能挣钱的交易。为什么这个是比较有价值的,因为很多时候攻击者可能会先去做一些攻击测试,这些测试攻击本身不一定是能够使得攻击者获利,但是攻击者只要把这个攻击交易的一些参数改一改,比如说把他的金额设稍微大一些,那么这个就立刻变成了一个获利交易。然后传统的很多基于规则的算法会去试图检测一个交易能不能获利,但是这样的话就会漏掉很多这种测试性质的交易,但是 BlockGPT 可以做出检测。
最后一点是因为 BlockGPT 是一个基于 Transformer 的模型,所以它其实能够给一个交易的每个部分都生成一个对数值,它可以告诉你这个部分它是不是正常或者是不正常的,所以说它其实可以更加具体的告诉我们这个交易到底有没有问题?当然,它的一个限制是只能告诉我们这个可能性,它目前还不能告诉我们,到底为什么有不正常的地方,这个部分还是需要人来去做检测。
接下来介绍一下我们的数据集,我们数据集主要是未经标注的一个交易数据集,这个数据集用来预训练 BlockGPT。数据集当中包括总共有大概 6800 万笔交易,这些交易是所有的我们已知受攻击的 DeFi 应用上发生的交易,这些交易总历时大概是 1523 天,然后从大概区块高度 500 多万直到区块高度 1500 万。然后在这个未经标注的数据集以外,我们有一个很小的有标注的数据集,这个有标注的数据集仅仅是用来去测试 BlockGPT 的有效性,然后这个数据当中就是我们所有已知的攻击交易。总共有 124 个 DeFi 应用被攻击过。然后就我目前已知的情况而言,所有的 DeFi 应用都只被攻击了一次,但是有很多攻击它是在多笔交易当中完成的,一般来说,这种情况就是前几笔交易会是测试性的攻击,然后最后或者最后几笔交易会是真正造成用户损失的攻击。在这种情况下我们假设只能够检测到其中的一个交易,我们就认定 BlockGPT 可以检测到这个攻击,因为它们的交易基本上其实是一样的,就只是一些参数做修改,导致有的交易可以获利,有的交易就基本上不获利。

接下来是一些关于数据集比较具体的统计数据,在这 124 个受攻击的 DeFi 应用当中有 42% 的攻击是源于智能合约层面上的一些漏洞,然后还有 40% 是来自于协议设计方面的漏洞,比如说攻击者可能会去操纵预言机,还有 30% 比较五花八门的攻击手段。在这些受攻击的 DeFi 应用当中,最小的一个应用它只有四笔交易,最大的一个 DeFi 应用已经有将近 60 万笔交易,具体的交易数量分布如上图所示。如果一个应用它的交易数量比较多的话,BlockGPT 就可以比较容易判断什么是正常,什么是不正常。如果它交易数量比较少的话,对于 BlockGPT 就相对而言会难一些。

下面简单介绍一下我们主要应用的技术手段,也就是 Transformer 还有语言建模。语言建模简单来说是给定给定一个符号序列 X1 到 Xn,它是来自于某一种语言,如果我们要对这个语言进行建模的话,我们其实就需要找到这个序列出现的可能性。语言建模的一个工具可以是 Transformer ,它其实是一个多层的神经网络,它最大的特点是它会使用 self-attention,它的输入就是这样一个符号序列,然后它的输出就是我们想要得到的结果。经过 Transformer 之后,它就可以用来做语言建模了,然而进行最大自然性估计,给定一系列符号序列我们来最大化攻击模型对他们的自然性估计。

接下来介绍一下 BlockGPT 整体的架构。第一步是用我们准备的训练数据,主要是我们爬一些历史上的交易,然后我们爬到交易之后会生成一些信息,包括函数调用和一些异常分析。Opcode 是一种汇编语言,还有一些状态更改的 trace 最后生成的事件记录。然后这些信息我们会把它全部处理成一个可以输入的数字符号,然后我们会经过词汇转化向量。这个向量可以进行 Transformer 输入。具体来讲它其实也挺简单的,就是它会反复地叠加不同层。第一个层是 Self-Attention 的输入和输出相加,然后做一个 identical layers,待会有一个公式具体讲到这个过程。接下来就是一个 Feed Forward,一个比较基本的神经网络结构,然后最后会再做一次相加。在这之前,我们会加入一个 Tree Encoding,它的作用是把整个数的结构生成向量表示,使得 Transformer 可以去识别这个数的结构。
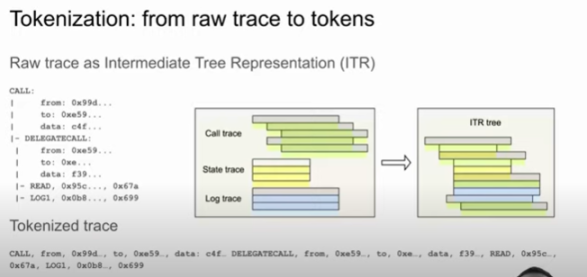
具体的话第一步我们会做 Tokenization。我们会把每次交易的 trace 转化成一个符号序列。上图就是一个比较简单的例子。Tokenization 过程会遇到一些问题,比如说一个比较简单的问题是 transformer 它一般只能够处理数量比较少的代币序列,500 到 1000 是比较常见的。虽然说是比较新的模型,像 GPT4 可以处理上万个符号,但这样的话回非常显著的增加它的运行开销。如果我们毫无删减的放 trace 进去就会比较吃力,我们的解决方法是只加入高层次的函数调用,还有一些经过筛选的最有信息含量的底层指令,比如事件记录、EVM 内存的读和写等。

接下来讲一下我们怎么样用 transformer 生成向量表示。Transformer 的输入我们刚刚讲的是一个符号序列,最原始的输出它其实是一个序列的向量表示。它生成向量表示需要通过两个操作,一个是 Self-attention,一个是 Position-wise Feed-Forward。这两个操作被重复了八次,大概有十亿个参数,这个数量级大概相当于 GPT2 的水平,因为我们的计算资源也不是很充裕。

具体的话就是 Self-attention 这个步骤会给每一个符号生成三个向量表示,包括查询向量、键向量和值向量,而这三个向量直接经过线性变化得到。有了这三个向量,我们就可以计算从符号 i 到符号 j 的 Token Attention,我就叫它正比于键和值向量的内积,除以维度的根号。除根号主要是起到一个保证数值稳定性的作用,大家可以暂时忽略掉它。得到内积结果后再次通过指数函数获得最终结果。有了 Token Attention 之后,新的向量表示就是可以通过这个的方式生成。我们首先对所有的值向量做一个加权平均,然后进行正态分布变化,保证它的平均值是 0,方差是 1。

接下来是 Position-wise Feed-forward,它是一个比较经典的两层神经网络结构,只不过它是把每个符号向量表示都包含在神经网络当中,然后大家可以看到这个神经网络其实就是一个常见的两层神经网络,它的激活函数是取第一层输出当中大于零的部分。之后会进行与之前相同的步骤来得到新的向量表示。

我们经过重复这两个操作之后,会得到一系列的向量表示。我们有了这些向量表示之后就可以进行模型计算。我们既可以计算出在预训练阶段的显示函数,也可以计算出在排序的时候每一个交易的可能性。我们会通过可能性来判断一个交易是否是异常的。

接下来再重复一下我们的异常检测方法。具体来说有两种方法,一种是我们给每个 DeFi 应用指定一个百分比,然后 BlockGPT 就会把所有交易当中最不可能百分之α列成异常交易,这种方法适用于交易数量比较少的 DeFi 应用。还有一种是绝对排序,也就是说我们会把最不可能的 K 个交易标为异常交易,K 是一个整数,适用于较为成熟的 DeFi 应用。
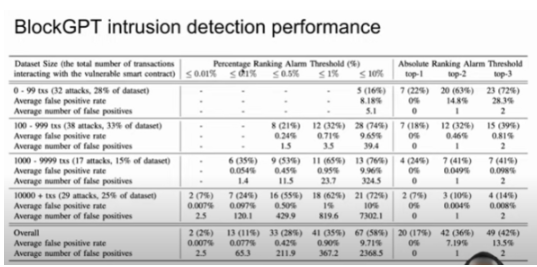
接下来就是我们实验的结果。根据刚我们讲两种不同的方法,我们也报告两个统计数据。第一个给定百分比,我们能够检测到多少个攻击交易?第二个给定一个绝对排序,也就是最不可能或者是前两个最不可能或者是前三个最不可能,然后我们能够识别出多少个攻击交易呢。我们总共是有 124 个攻击交易,大家可以在上图中看到结果。如果指定只看前三个最不可能的异常交易,BlockGPT 其实已经可以识别出相当数量的攻击交易。如果是指定不同的百分比的话,比如如果它只标注 0.5% 的交易为异常价的话,在攻击数量比较多、比较成熟的一些应用中更加有效。
我们还报告了平均假阳性率和平均假阳性个数的统计数据,它可以比较直观的告诉我们,使用 BlockGPT 作为异常检测工具的话,会给每一个地方应用造成多少的额外开销。如果它的假阳性率比较高的话,那么相应的额外开销就会比较高一些,因为每一个假阳性报告都需要人工来检测,所以人力成本其实是这里面主要的一个考量因素。
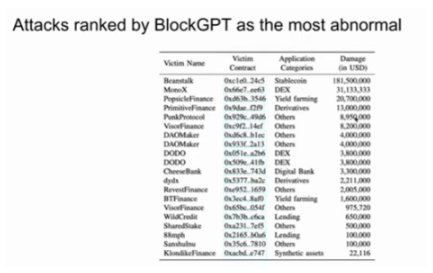
表格当中列举了一些被 BlockGPT 排为最不可能的异常攻击交易,可以看到这些攻击交易造成了非常高的经济损失。
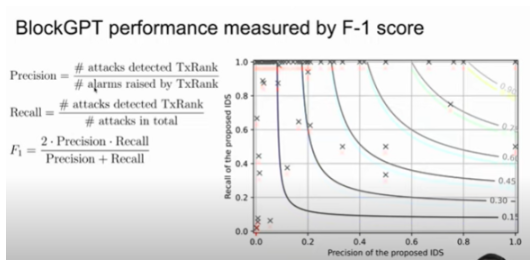
我们这里的 F-1 score 采用了比较很经典的定义,这里面 Precision 指的是被检测攻击数量除以警报量,Recall 指的是被检测攻击数量除以总攻击数量。通过上图可以看到它基本上能够检测到所有的交易。在我们应用场景当中,假如说有一个攻击它没有被检测,就会造成很高的经济损失。如果 BlockGPT 给出一个错误的警报,它确实也会造成额外的开销,但是这个额外开销相比于攻击没有被检测到的损失,其实它其实是九牛一毛的。当然这个开销不可忽略,毕竟还要不停的运行 BlockGPT。

接下来我会讲两个具体的攻击实例。在第一个实例是 Beanstalk 应用在 2022 年 4 月份遭到的攻击。攻击者首先是通过 Aave 的闪电贷借出十亿美元,然后通过借出的钱获取了项目 67% 的投票权。他利用他手中的投票权把整个协议存款提空。他在这一切操作完成之后,他又把借的钱还了回去,整个交易是可以被执行的。这次攻击其实是可以在 P2P 网络上直接被观测到的,在整个区块被确认之前,需要 30 秒钟。在这种情况下,我们就可以使用 BlockGPT 来检测这个交易,至少我们有一个 30 秒钟的窗口来阻止这个交易,BlockGPT 本身的运行时间其实是非常快的,如果它只需要处理一个交易的话,它的运行速度是在毫秒级的,基本上这 30 秒钟就可以完全留给 DeFi 应用来做一些应急的措施。

第二个例子是 Revest 合约,在这个合约当中它的交易其实并不是通过 P2P 网络广播的,它是预言机攻击的一种,在这个情况下,我们就不能在第一次攻击交易写入区块链之前检测到这个交易。大家可以看到这个交易它其实总共有四笔攻击交易,也不是在同一个区块,前后隔了将近 70 个区块。也就是说我们总共有 70 个区块的时间留给 BlockGPT 做出检测,并阻止后面攻击交易的发生。

最后,我们把 BlockGPT 和一些其他已有的异常检测系统做了一个对比。我们对比的维度主要有以下几点:第一个是否需要明确的信息,不同的工具其实不尽相同,BlockGPT 确实需要一定的历史交易信息,但是它不需要人工对这些历史交易进行分析。其他的一些工具一般来说还需要人去制定一些基于历史交易的规则。接下来是搜索的空间,BlockGPT 可以对所有的交易进行搜索,但是其他一些工具一般来说就只能搜索一些能够获益的交易,或者是一些规则能够覆盖到的一些交易。然后接下一个维度是否保持实时检测,基本上这些都是实时。BlockGPT 它会稍微慢一点,因为这个数字是我们没有经过对系统进行优化的结果,所以如果优化的话,它其实速度还可以会更快一些。最后是是否能够应用到所有的 DeFi 应用当中,BlockGPT 是没有问题的,剩下的这些工具有一些是可以,有一些是不太行的。
发布者:Web3创投,转载请注明出处:https://nft.aiju.com/news/80641.html,如涉及作品内容、版权及其它问题,请联系本站!
『声明:根据央行等部门发布的《关于进一步防范和处置虚拟货币交易炒作风险的通知》,本文内容仅用于信息分享,不对任何经营与投资行为进行推广与背书,请读者严格遵守所在地区法律法规,不参与任何非法金融行为』