


互联网发明最大的意义莫过于让人人都能驰骋在信息高速公路上,并且在80年代时与PC共同拉开了第三次科技革命的大幕,人类社会迎来了前所未有的高速发展。时代与个体都被这场革命裹挟着前进,互联网在经过了Web1的只读,Web2的读写与创造,以及前所未见的移动互联网后,现在新时代和Web3呼之欲出,即将再次改写人类社会进程。
Web3的确切模样没人知道,但目前可以确定的是它包含下列三个显著特征:
一、拥有10M的平均带宽;
二、个人门户网站及相关服务,运营商提供基于用户偏好的个性化聚合服务;
三、个人和组织间建立一种互为中心而转化的机制,个人也可以实现经济价值。
基于这三个特征又可以细分出多个发展领域或赛道,美国企业家兼风险投资家Nova Spivack(诺瓦·斯皮瓦克)建议将Web3的定义延伸至当前各大技术潮流迈向新的成熟阶段的具体体现。值此年后开工大吉之际,本周就来窥探一眼未来Web3可能的发展前景,或者今人正致力于解决的问题。注意,本系列中有许多电脑和网络科学专有名词。今天是第四期,智能APP与机器学习。
一、自然语言处理系统
自然语言处理(Natural Language Processing,简称NLP)是AI和语言学交叉后形成的分支学科,探讨如何处理及运用人类的自然语言,包括多个方面和步骤,简单的说有对语言的认知、理解、生成等部分。此项目着眼于让电脑把输入的语言变成可理解的符号和逻辑关系,然后根据目的或需要再作后续处理,与之相关的自然语言生成系统则是把电脑数据转化为自然语言。
NLP基本公认始于上世纪50年代,虽然更早期也有相关研究。1950年,研究AI的先驱图灵发表论文《计算机器与智能》,其中提出后世著名的“图灵测试”作为判断AI智能程度的条件。1954年,由乔治城大学与IBM合作进行的“乔治城-IBM实验”将超过60句俄语顺利翻译成英语,并声称在三到五年之内即可解决机器翻译的问题。虽然翻译的很成功并被各大媒体蜂拥报道,引起全球的广泛关注,美国、苏联、欧洲等都开始大力投资机器翻译与语言投资领域,但事实证明所谓的“三到五年”不过又是人类展示了次自己的傲慢与无知。
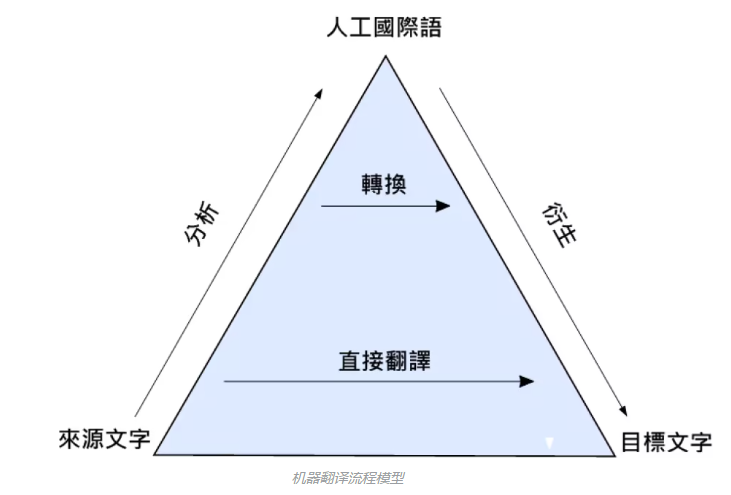

1964年,美国科学院成立了语言自动处理咨询委员会(AutomaticLanguage Processing Advisory Committee,简称ALPAC)开始为期两年的综合调查分析和测试。两年后ALPAC的报告表明这十年的研究根本没有达预期目标,美国直接大砍机器翻译的研究经费。一直到1980年代末期,“统计机器翻译系统”发明为止,机器翻译的研究才得以更上一层楼。
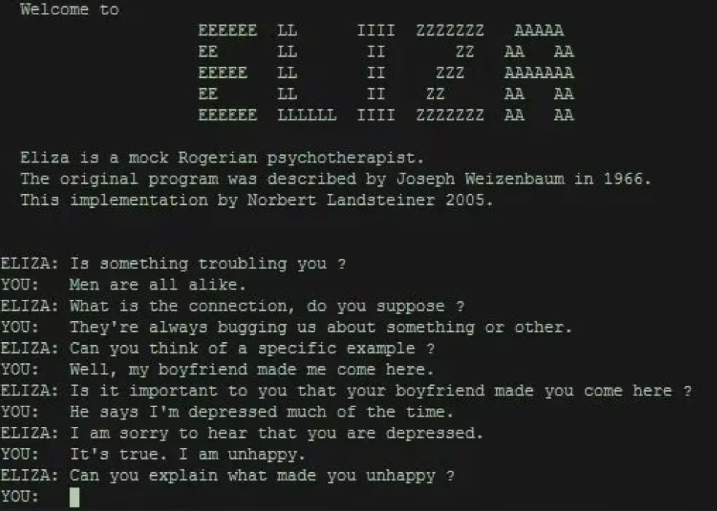
虽然机器翻译的牛皮吹破了,但60年代的NLP发展倒是有声有色,如SHRDLU程序,用户可以通过它与电脑进行简单对话;同时期的还有ELIZA程序,模拟“个人中心治疗”而设计的对话系统,其中几乎不涉及人类思想和感情的消息,有时候的回答却很像真人。但是当“病人”提出的问题超出ELIZA本来就极小的知识范围之时可能会得到空泛的回答。比如说“我头很痛”,它的回答是“为什么你说头痛?”
70年代开始有程序员设计“概念本体论”(conceptual ontologies)的程序,将现实世界的信息编译成电脑能够理解的资料,许多聊天机器人都是在这一时期写成。一直到80年代,大多数NLP都是以一套复杂、人为预定的规则为基础。不过从80年代末期开始,语言处理引进了机器学习的算法,NLP才产生革新。原因主要有二:摩尔定律的稳定发挥;新的语言学理论开始出现。
理论上说来,NLP是一种很吸引人的人机交互方式。但是又因为理解语言需要关于外在世界的广泛知识以及运用、操作这些知识的能力,因此自然语言认知同时也逐渐发展成AI完备性的问题。而且在自然语言处理中,“理解”的定义也逐渐演变成一个主要的问题。举个例子,有个经典笑话说某老外苦学汉语十年,到东方某大国参加汉语考试最终含泪交白卷。试题为“请解释下列句子中‘意思’的含义”:
阿呆给长官送红包,长官:“你这是什么意思?”
阿呆:“没什么意思,就是意思意思。”
长官:“你这就不够意思了。”
阿呆:“小意思,小意思。”
长官:“你这人真有意思。”
阿呆:“其实也没有别的意思。”
长官:“那我就不好意思了。”
阿呆:“是我不好意思。”
不少中文笑话都利用类似结构的造句,此类笑话通常暗含“中文博大精深”之类的含义。虽然只是笑话,但由此也可以看出NLP目前的难点:词汇的边界与界定(在表意为主的汉语中尤其困难);词义的变迁与歧义;语法的模糊性;无标准或不规范的输入(如各种方言间的差异);语言与行为间的冲突等等。
去年底时聊天机器人ChatGPT和背后的OpenAI以前所未有的速度火出圈,最近又有拥趸在摇旗呐喊,说2023将是ChatGPT之年。本人还是保持之前泼冷水的态度,或许它在今年能取得一些发展或成就,但离预期目标还差得远。另外本人也相信明年还会有人说2024将是ChatGPT之年,后年还会有人说2025将是ChatGPT之年,不信就请拭目以待。

西方有句谚语:“人类一思考,上帝就发笑。”回顾NLP与AI产业发展的这几十年,再看这句谚语还真有意思。《圣经·旧约全书·创世纪篇》中记载,一群只说一种语言的人在“大洪水”后从东方来到了示拿地区(今伊拉克等国的两河流域,古希腊称美索不达米亚),并决定修建一座城市和一座“能够通天的”高塔;上帝见此情形就把他们的语言打乱,让他们再也不能明白对方的意思,并把他们分散到了世界各地。而这几十年里人类一直在思考怎么能让电脑学会人类智慧。
二、机器学习,推理与自主代理
机器学习是AI产业的一个分支,AI的发展历程有着一条非常明晰的主线,从一开始的以“推理”为重点,后来以“知识”为重点,再到现在的以“学习”为重点。显而易见的,机器学习也是AI实践与应用的途径之一,即以机器学习为手段,解决AI中遇到的问题。机器学习经过三十多年的发展,已经成为一门多领域交叉学科,涉及概率论、统计学、逼近论、凸分析、计算复杂性理论等学科。
机器学习可以分成下面几类:
监督学习:从给定的训练数据集中学习出一个函数模型,再遇到新的数据时就可以根据这个函数模型预测结果。监督学习的训练集要求是包括输入和输出,或者说是特征和目标。训练集中的目标是由人为设定的,这种算法的应用最普遍,包括回归分析和统计分类等。
无监督学习:与监督学习相比,无监督学习的训练集没有人为设定的结果,这种学习常见的算法有生成对抗网络(GAN)、聚类分析等。
半监督学习:介于前两者之间的算法。
增强学习:为了让机器达成目标,随着外部环境的变动而逐步调整其学习行为,并在每个行动之后评估回馈,看是正向或负向的,并以此为依据再结合调整学习行为。
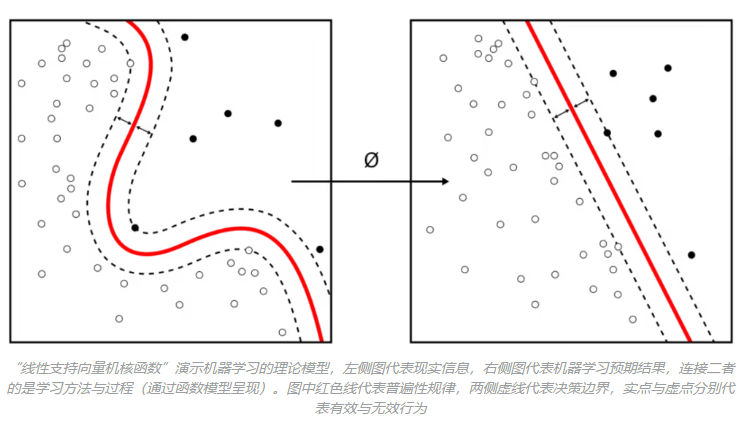
从本质上说,机器学习算法是一类从数据中自动分析和获得规律,并利用规律对未知数据进行预测的算法。因为其中涉及了大量的统计学理论,所以机器学习与推断统计学的联系尤为密切,这也被称为“统计学习理论”。机器学习目前已广泛应用于数据挖掘、电脑视觉、电脑语言、生物特征识别、搜索引擎、医学诊断、反诈、证券市场分析、DNA序列检测、语音和手写识别、游戏和机器人等领域。
【文章来源】
发布者:Web3创投,转载请注明出处:https://nft.aiju.com/news/50950.html,如涉及作品内容、版权及其它问题,请联系本站!
『声明:根据央行等部门发布的《关于进一步防范和处置虚拟货币交易炒作风险的通知》,本文内容仅用于信息分享,不对任何经营与投资行为进行推广与背书,请读者严格遵守所在地区法律法规,不参与任何非法金融行为』